Warm HA Setup, Failover, and Automated Backups
The Device42 Warm High Availability (HA) configuration allows you to put a second appliance on standby mode and do periodic restorations to the device for use as a failover.
Automate Restores to Back Up Your Main Appliance for Warm HA
This process consists of two steps:
- Setting up the automated restores
- Setting the backup appliance to production mode in the event of a device failure
From the Device42 Appliance Manager, you can set up automated restores to a backup appliance. This is done by setting the appliance to standby mode and configuring the appliance to restore from a backup file on a remote server. The appliance will then automatically restore from the backup file at specified intervals.
Set Up Automated Restores for a Warm HA Appliance
Log in to the Appliance Manager and navigate to Global Settings > Appliance Mode. You will see the following screen with the option to Enable Standby:
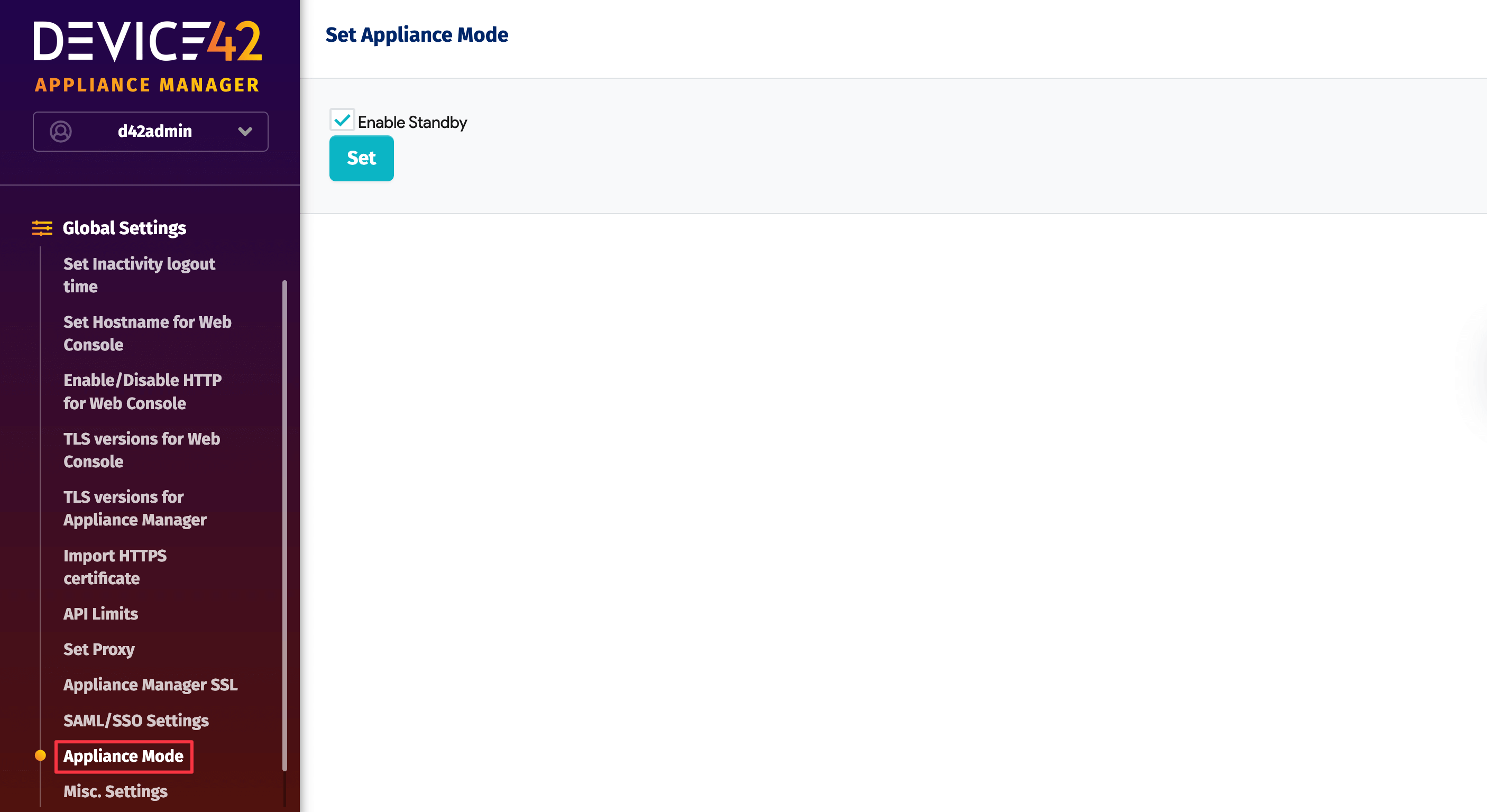
You can declare an appliance to be in standby mode and then enable regular restores from either an NFS export or an SFTP location. Putting the appliance in standby mode does the following:
- Disables the background scheduler that runs the autodiscovery jobs
- Disables scheduled reports
- Disables backups from the appliance
You can add the auto-restore schedule using crontab syntax. Configure the interval for how often you want the secondary appliance to pick up the backup file from the remote server.
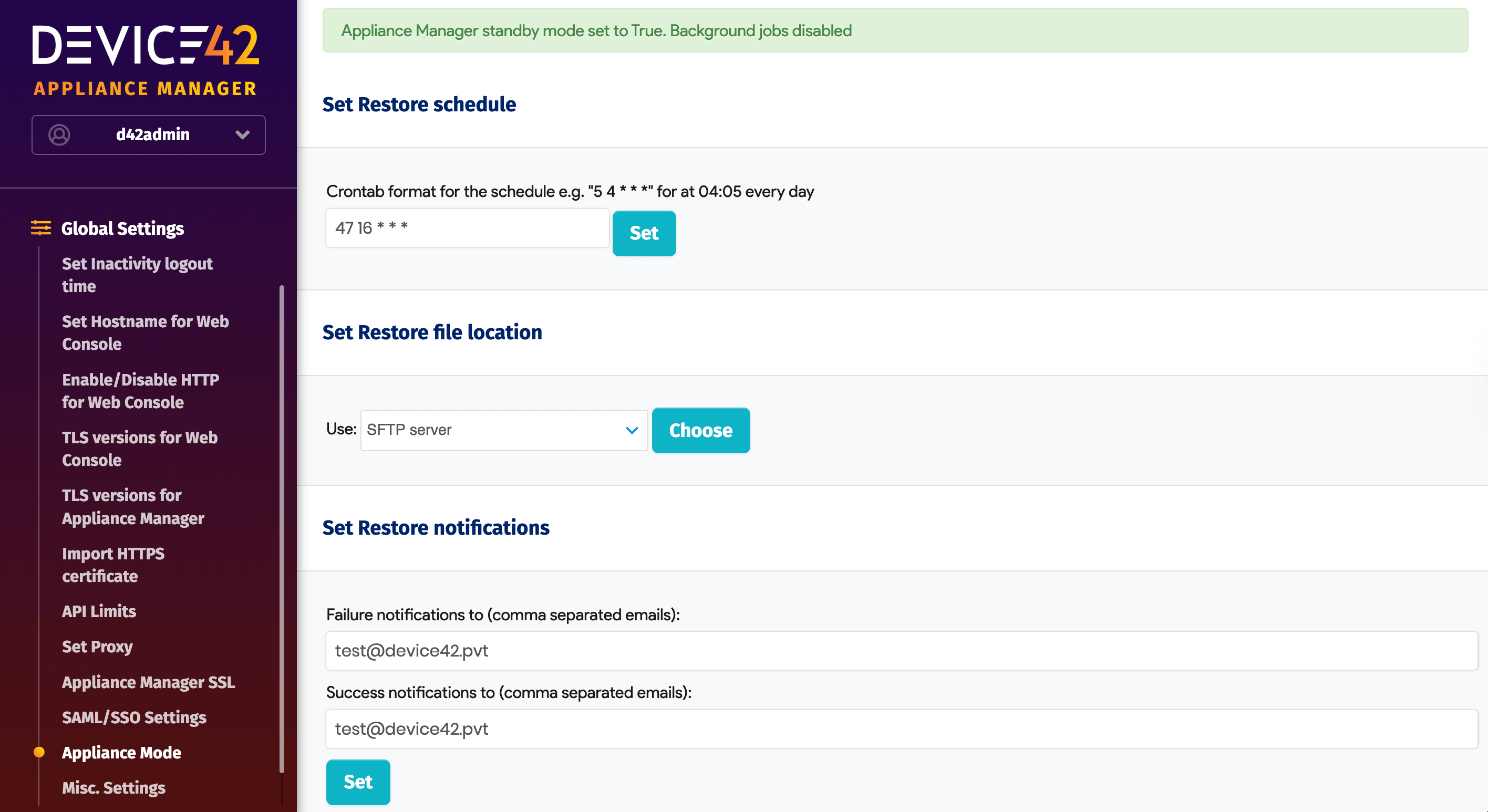
The credentials you use for the passphrase, SFTP server settings, and the backup file name should be identical on both the production and the standby appliance. You can use Amazon S3, NFS, and SFTP as backup locations.
The NFS and SFTP paths, their credential settings and the S3 settings are configured in their respective sub-menus in the Device42 Appliance Manager. Once you have chosen your restore method, look for NFS Server Settings, SFTP Server Settings, and Amazon S3 Settings in the left sidebar:
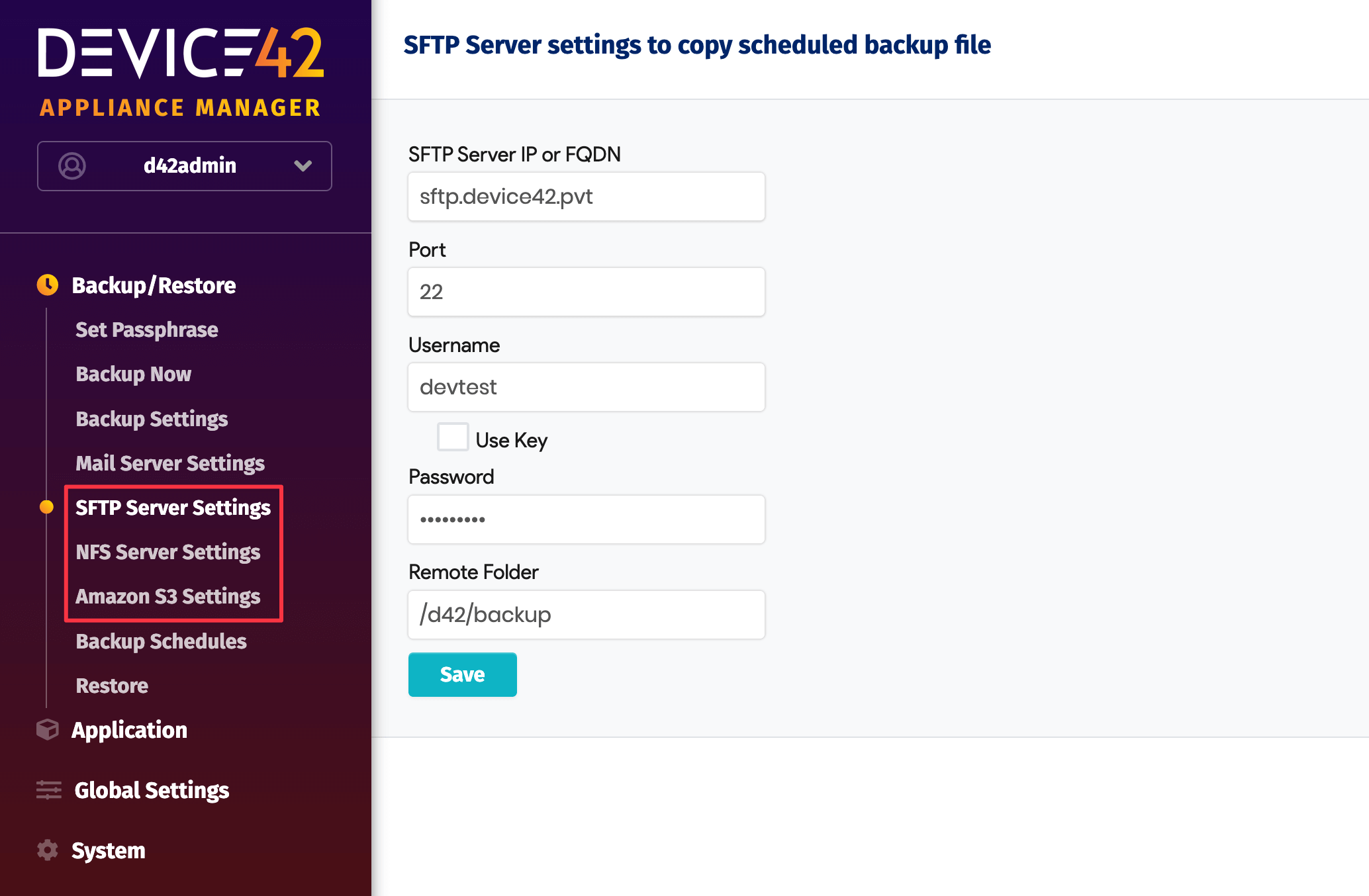
While doing an auto-restore, all schedules get disabled, so if another auto-restore falls within the same window, it will not kick off. To let you know whether an auto-restore has succeeded or failed, we have also added success and failure notifications. Mail server settings must be set for these notifications to work.
Important Note for Backup Schedules with Auto-Restore
Any attempt to auto-restore from a backed-up file will fail if the metadata is not included in the backup.
It is critical that you select to include Backup Meta Data as an option under Backup schedules for backups to your SFTP, NFS, or S3 storage.
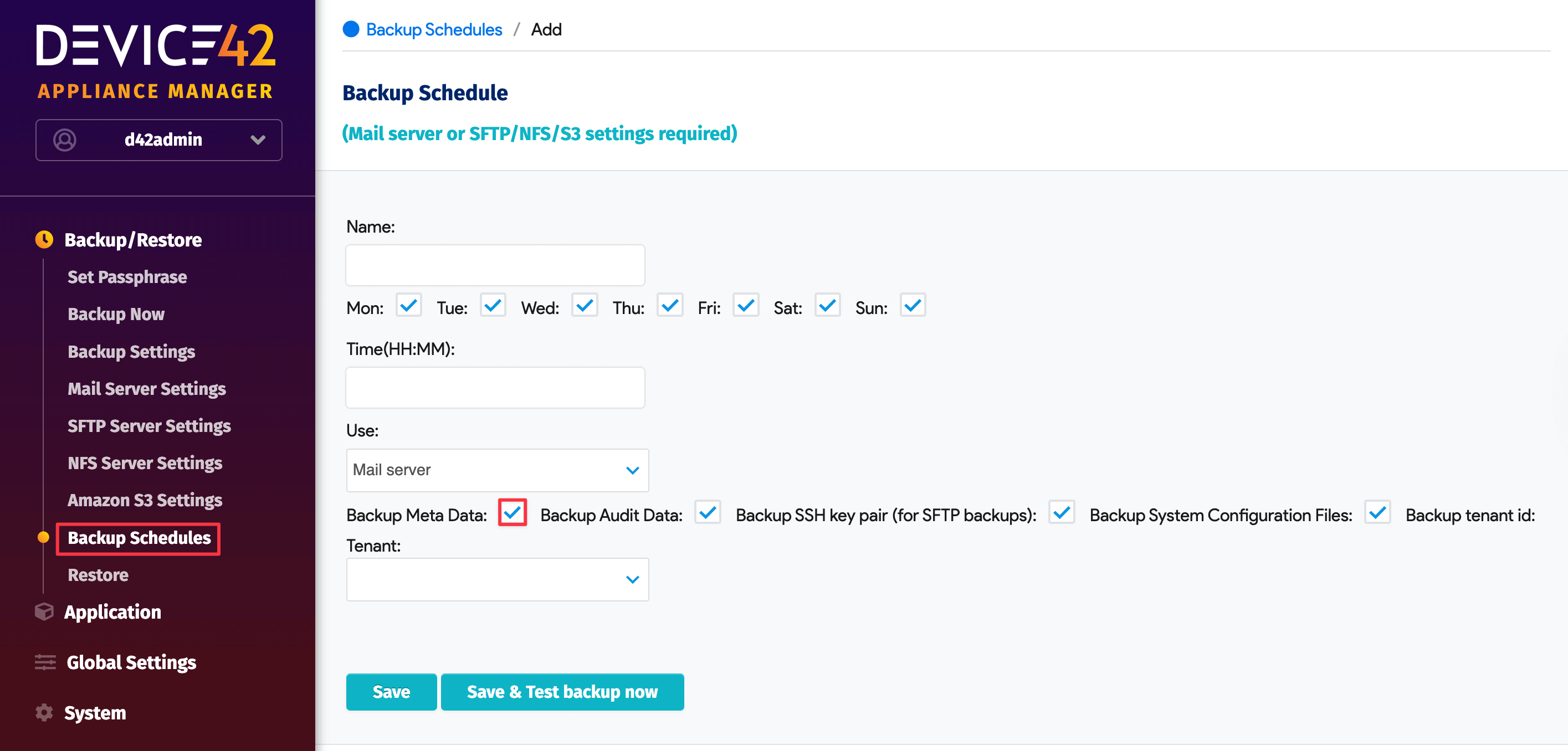
Without the metadata, restore and passphrase settings will not be included in the backup archive and the appliance will have no reference for using the data when attempting to restore from schedule.
A backup file without metadata can still be used for an on-demand Restore.
Refer to the Device42 docs to find additional details about backup metadata and scheduling the backup.
Set Appliance Mode via API
With automated restores in place on your backup appliance, you're ready to set the backup appliance to production mode in the event of a device failure. You can send a POST call to /api/1.0/appliancemode/ with the payload appliance_mode=production or appliance_mode=standby to set the appliance to production or standby mode. This is intended to be triggered from the monitoring software of your choice (see the example below). After switching, a simple update to the DNS settings to point your domain to the new production instance IP will facilitate continuous use of Device42 without downtime.
Automatic Failover Using Your Monitoring System
When running Device42 in HA mode with a warm standby configured, in the event of primary instance failure, the secondary instance must be promoted from the warm standby state (with job processing, scheduler, and backups deactivated) to a primary (and fully active) state. A Device42 appliance instance can be toggled from warm standby mode to production mode and back again with a simple API call.
To toggle between warm standby and production, simply pass the appliance_mode parameter in a POST call to the following API endpoint: /api/1.0/appliancemode/.
- Sending the
appliance_mode=productionparameter will toggle a warm standby appliance to production mode. - Sending the
appliance_mode=standbyparameter will toggle a production appliance to warm standby mode.
For example, the following API POST call toggles a Device42 appliance instance from standby to production with curl:
curl -X POST -d "appliance\_mode=production" -u 'd42admin:default' https://Device42Instance:4343/api/1.0/appliancemode/ --insecure

By embedding the above call in a script that is called in response to a failure event detected by your monitoring system, the failover process can be fully automated.
Nagios Automated Failover Example
The following example uses Nagios along with the above example API call to automatically switch a Device42 backup appliance from warm standby mode to production mode in a failover scenario.
-
First, add the following configuration GitHub link to your Nagios host file:
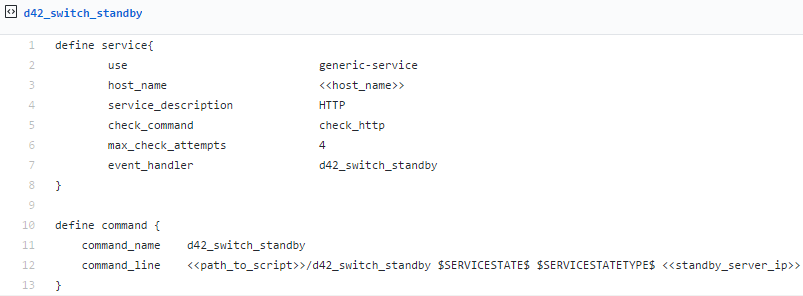
-
Then, create a script file similar to this example GitHub link:
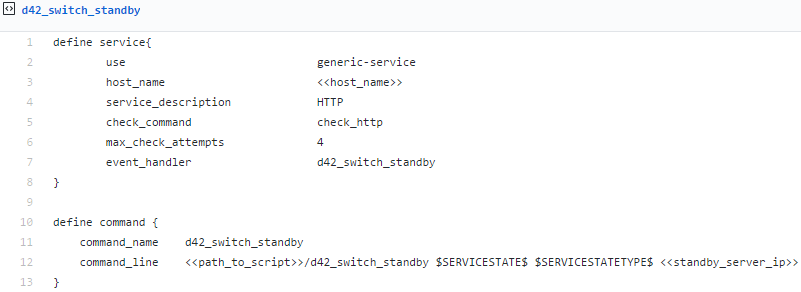
If used exactly as written, the example script only enables automated failover to the secondary instance, and not to failback. The provisions to failback are present in the example script but are currently commented out, as can be seen in lines 11 and 12. Though it may be unnecessary, depending on the failure mode of the primary instance, it’s not a bad idea for your production script to attempt to send an API call to place the primary instance on standby mode as a precaution. Setting the primary instance on standby will prevent it from running jobs should it recover before a failback is intentionally initiated.
- Please ensure the script runs as the proper Nagios user, and is also allowed the
$ chown nagios:nagios <> && chmod 755 <>execution permissions. - The current example works by using
check_httpto detect failure, but it is possible to change it to use other commands. - The production DNS entry must be edited to point at the IP of the new primary Device42 instance to allow reachability via the same URL. For Windows DNS environments, this can be accomplished with the following powershell example script (you can see usage examples by the script's author in this blog post). For other platforms, you will need to write and use a custom script.
How it works: If the main Device42 server instance goes down and the failure is detected by monitoring, the above script switches the appliance mode of the secondary server to production mode with a POST call to the /api/1.0/appliancemode/ RESTful API endpoint with the payload appliance\_mode=production. If the main server comes back up again, the script can switch the secondary appliance back to standby mode, allowing the first server to once again become authoritative. Uncomment lines 11 and 12 to allow this to happen automatically. Ensure that you have also made provisions to switch the DNS entry back to the primary instance’s IP address.